
2017/04/28 Training
Hôm nay có hai phần: bài thầy Hoàng và bài anh Khuê. Cả 2 đều cần một sự tay to nhất định.
Tóm tắt đề bài
select (thầy Hoàng)
Cho dãy \(S\) gồm các kí tự d và x. 2 người lần
lượt chơi, mỗi lượt bốc 1 kí tự, kí tự này phải đứng
cạnh 1 vị trí đã bị chọn trước đó (trừ nước
đầu tiên được chọn thoải mái). Khi trò chơi
kết thúc, người đi trước thắng khi có nhiều d
hơn hẳn người kia. Đếm số vị trí ban đầu
mà người đi trước có thể chọn mà vẫn đảm bảo
chiến thắng?
Giới hạn
\(1 \le |S| \le 1000\).
eureka (thầy Hoàng)
Cho một hệ thống cân đĩa được biểu diễn như sau:
- Nếu chỉ gồm
-1: Đây là một vị trí đặt quả cân. - Là một cái cân có dạng
x y A Btrong đó \(x\) và \(y\) lần lượt là độ dài cánh tay đòn bên trái và bên phải của cân; \(A\) và \(B\) là 2 hệ thống cân được treo vào bên trái và bên phải của cân.
Hình dưới biểu diễn hệ thống cân được biểu diễn
bằng dãy 12 18 4 2 -1 -1 10 8 3 3 -1 -1 6 4 -1 -1:
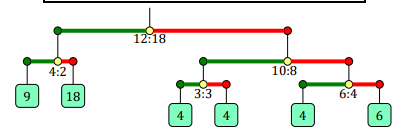
Trọng lượng các quả cân đều phải là số nguyên dương.
Hãy tìm trọng lượng cho các quả cân của từng vị trí đặt sao cho tất cả các cân đều thăng bằng và tổng trọng lượng các quả cân phải đặt là nhỏ nhất. Giả sử cân không có trọng lượng.
In ra tổng nhỏ nhất lấy dư cho \(123456789\).
Giới hạn
Miêu tả được cho bởi dãy \(A[1..N]\).
\(1 \le N \le 3 \times 10^5\), \(A[i] = -1\) hoặc \(1 \le A[i] \le 100\).
liondance (thầy Hoàng)
Cho 2 dãy số \(A[1..N]\) và \(B[1..N]\). Tìm dãy con chung dài nhất sao cho 2 phần tử liên tiếp chênh lệch nhau không quá \(d\).
Nếu có nhiều dãy, in ra dãy có thứ tự từ điển lớn nhất.
Giới hạn
\(1 \le N \le 4000\), \(1 \le A[i], B[i] \le 10^9\)
desert (thầy Hoàng)
Trên mặt phẳng cho \(N\) điểm. Tìm đường đi từ \(1\) đến \(N\) sao cho khoảng cách Manhattan lớn nhất giữa 2 điểm liên tiếp đi qua là nhỏ nhất.
Giới hạn
\(1 \le N \le 10^5\), tọa độ \(-10^9 \le X_i, Y_i\le 10^9\)
Trốn việc (anh Khuê)
Cho dãy số \(A[1..3N]\), chọn ra tập số có tổng lớn nhất sao cho trong \(N\) số liên tiếp bất kì có không quá \(K\) số được chọn.
Giới hạn
\(1 \le N \le 200\), \(1 \le K \le 10\), \(1 \le A[i] \le 10^6\)
Party1 (anh Khuê)
Cho \(N\) bạn nam và \(M\) bạn nữ, và \(K\) mối quan hệ nam - nữ. Liệt kê tất cả bạn nam và bạn nữ chắc chắn sẽ xuất hiện trong cặp ghép cực đại.
Giới hạn
\(1 \le N, M \le 10^4\), \(1 \le K \le 10^5\).
Party2 (anh Khuê)
Cho đồ thị \(N\) đỉnh \(M\) cạnh xanh \(K\) cạnh đỏ, đỉnh \(i\) có trọng số \(A[i]\). Chọn một tập điểm có tổng trọng số lớn nhất thỏa mãn:
- 2 đỉnh có cạnh xanh nối giữa thì không được cùng chọn.
- 2 đỉnh có cạnh đỏ nối giữa thì cùng được chọn, hoặc cùng không được chọn.
Đồng thời, đếm số cách chọn tối ưu.
Giới hạn
\(1 \le N \le 250\), \(0 \le M \le \frac{N(N-1)}{6}\), \(\frac{N(N-1)}{3} \le K \le \frac{N(N-1)}{2}\)
Lời giải
select
Chuyển đổi bài toán
Rất khó quản lí trạng thái thắng thua khi bài toán yêu cầu so sánh số lượng. Vì vậy, ta sẽ biến đổi bài toán một chút - mặc dù tính chất thắng - thua không thay đổi.
Thay vì so sánh số lượng d của từng người,
ta lấy số lượng d của người đi trước trừ
đi người đi sau. Hiển nhiên người đi trước
muốn hiệu dương - tức đối đa hóa nó, và
người đi sau muốn tối thiểu hóa nó.
Bởi vì đây là trò chơi hữu hạn bước, và 2 người đều phải chơi tối ưu, nên ta sẽ chỉ đi tìm một kết quả duy nhất: hiệu tối ưu của trò chơi, với mỗi cách chọn bước đầu.
Quy hoạch động
Gọi \(f[l][r]\) là hiệu tối ưu của trò chơi, nếu trò chơi bắt đầu với trạng thái đoạn \(l..r\) bị khuyết. Ta có:
- Hiển nhiên \(f[l][r] = 0\) nếu \(l..r\) đã phủ toàn bộ vòng tròn.
- Ta có thể hiểu độ dài \(l..r\) sẽ tương đương với số bước đã xảy ra, vì vậy ta có thể biết được lượt đi tiếp theo là của ai.
- Nếu đây là lượt của người đi trước, hẳn hắn ta sẽ muốn \(f[l][r]\) lớn nhất có thể, tức hắn sẽ chọn vị trí \(l - 1\) hay \(r + 1\) sao cho \(f[l - 1][r]\) hoặc \(f[l][r + 1]\), cộng vị trí hắn chọn nếu nó màu đỏ, sao cho tổng ấy lớn nhất có thể. Nói cách khác ta có: \[ f[l][r] = \max(f[l - 1][r] + (\text{S[l - 1] == ’d’}), f[l][r + 1] + (\text{S[r + 1] == ’d’}))\]
- Ngược lại, người đi sau sẽ muốn lựa
chọn của mình là nhỏ nhất có thể, tức:
\[ f[l][r] = \min(f[l - 1][r] -
(\text{S[l - 1] == ’d’}), f[l][r + 1] -
(\text{S[r + 1] == ’d’}))\]
Lưu ý dấu
-, bởi ta đang tối ưu hiệu người đi trước trừ người đi sau.
Ta có thể tính tất cả các hàm \(f[1][1]\), \(f[2][2]\), …, \(f[N][N]\) trong độ phức tạp \(O(N^2)\).
Đếm vị trí tốt
Một vị trí \(i\) thỏa mãn đầu bài nếu như
hiệu tối ưu lớn hơn \(0\), bởi khi đó người
thứ nhất luôn có thể làm cho mình có nhiều
d hơn. Như vậy, ta chỉ cần thử hết các
vị trí \(i\) và kiểm tra xem \(f[i][i] > 0\)
đúng không.
Tổng độ phức tạp của bài toán là \(O(N^2)\).
eureka
Tính chất của tổng trọng lượng
Xét một hệ thống cân, không khó để chứng minh tổng trọng lượng của nó phải là một bội của số \(X\) tương ứng với từng hệ thống.
Nhiệm vụ của ta là đi tìm \(X\) đó cho cả hệ thống lớn, bằng cách tính từ các hệ thống con.
Quy nạp
Hiển nhiên quả cân có thể nhận trọng lượng bất kì, vậy quả cân là hệ thống cân có \(X\) là 1.
Ta xét hệ thống cân \(a, b, X_l, X_r\) trong đó \(X_l, X_r\) là các giá trị mình đã tính trước đó cho hệ thống cân bên trái và phải. Ta có:
- Tồn tại \((p, q) = 1\) sao cho \(paX_l = qbX_r\). Hiển nhiên đây là \(p\) và \(q\) có tổng nhỏ nhất thỏa mãn.
- Khi đó, \(X = pX_l + qX_r\).
Ta có thể nhận thấy \(\frac{p}{q} = \frac{bX_r}{aX_l}\), vậy \(p = bX_r / d\) và \(q = aX_l / d\) với \(d = \gcd(aX_l, bX_r)\). Như vậy \(X = \dfrac{X_l X_r(a + b)}{d}\).
Số lớn
Ta nhận thấy từ công thức trên rằng đáp số có thể rất lớn. Ta không cần phải in số lớn, tuy vậy các phép tính như \(\gcd\) không thể được tính khi số đã bị mod.
Tuy nhiên ta cũng không cần phải cài số lớn: Mỗi lần ta nhân thêm một số \(a + b \le 200\), nên thay vì lưu số lớn ta sẽ lưu tập ước nguyên tố và số mũ. Khi đó, các phép nhân (cộng số mũ), chia (trừ số mũ), lấy \(\gcd\) (lấy min số mũ) trở nên đơn giản, với độ phức tạp \(O(A[i])\).
Ta có thuật toán đáp số với độ phức tạp \(O(N * A[i])\).
Cài đặt
Một cách cài đặt ngắn gọn là sử dụng đệ quy, vừa đọc vừa làm. Ta thực hiện lần lượt:
- Đọc \(a\) và kiểm tra xem có phải quả cân không. Nếu có trả về 1.
- Đọc \(b\).
- Đệ quy giải bên trái \(X_l\).
- Đệ quy giải bên phải \(X_r\).
- Tính và trả về \(X\).
liondance
Quy hoạch động
Về cơ bản, đây chỉ là bài toán LCS có thêm điều kiện, vì vậy hướng suy nghĩ của ta tất nhiên là cải thiện thuật toán quy hoạch động LCS, vì độ phức tạp yêu cầu cũng tương đương.
Vậy làm sao để quản lí trạng thái vẫn là \([i][j]\) khi ta còn cần thông tin về 2 phần tử liên tiếp? Ta sẽ cần “gói” nhiều thông tin hơn vào trạng thái \((i, j)\).
Thêm thông tin!
Ta sẽ định nghĩa hàm quy hoạch động như sau: Gọi \(f[i][j]\) là dãy con chung dài nhất khi sử dụng đoạn \(A[i..N]\), đoạn \(B[i + 1..N]\) và \(B[j]\) là phần tử cuối cùng được thêm ở đầu đoạn (để đơn giản, ta không tính cặp \(B[j]\) - ?? vào đáp số, cũng như coi \( B[0]\) là phần tử có thể ghép với mọi thứ).
Tại sao lại định nghĩa như vậy?
Nhờ có việc đánh dấu \(B[j]\) là số được thêm vào cuối cùng, ta có thể quản lí giá trị có thể thêm vào tiếp theo. Khi có \(f[i][j]\), và \(A[i] = B[k]\) (\(k \ge j + 1\)), điều kiện duy nhất đẻ kiểm tra chỉ là \(|B[j] - B[k]| \le d\).
Tại sao lại từ cuối?
Để giúp cho việc truy vết thứ tự từ điển, sau này mình sẽ nói đến.
Ta có thể tính hàm quy hoạch động này như sau - \(f[i][j]\) có thể được tính từ các trạng thái:
- \(f[i + 1][j]\), hiển nhiên
- \(f[i + 1][k] + 1\), với \(k \ge j + 1\) và \(A[i] = B[k]\).
Độ phức tạp là \(O(N^3)\). Ta sẽ cần một chút quan sát để hạ độ phức tạp.
Nhảy xuống \(O(N^2)\)
Khi xét \(f[i][j]\), ta có thể thấy nếu \(k \le k’\) và \(A[i] = B[k] = B[k’]\) thì \(f[i + 1][k] \ge f[i + 1][k’]\). Chứng minh rất đơn giản: \(B[k + 1..N]\) dài hơn \(B[k’ + 1..N]\), mà điều kiện ghép không đổi.
Vì vậy, thực chất ta chỉ cần tìm \(k\) nhỏ nhất thỏa mãn \(k \ge j + 1\) và \(A[i] = B[k]\) để cập nhật vào \(f[i][j]\). Việc này có thể thực hiện bằng việc đánh dấu khi for ngược \(i\) và \(j\), nên độ phức tạp chỉ còn \(O(N^2)\).
Thứ tự từ điển
Khi quy hoạch động \(f[i][j]\), ta sẽ lưu thêm \(nx[i][j]\) là chỉ số \(B[k]\) mà mình chọn làm kí tự tiếp theo. Do điều kiện của dãy đáp số là phụ thuộc vào giá trị chứ không phải chỉ số, ta sẽ phải thêm vào các điều kiện sau đây để đảm bảo lựa chọn chỉ số tiếp theo cho truy vết:
- Hiển nhiên nếu \(f[i + 1][j] \neq f[i + 1][k]\) thì ta chọn cái nào lớn hơn, vì được dãy dài hơn.
- Nếu bằng nhau, hiển nhiên trong \(B[nx[i + 1][j]]\) và \(B[k]\) cái nào lớn hơn ta chọn.
- Nếu vẫn bằng nhau, ta nhận thấy chắc chắn \(nx[i + 1][j] \ge k\), do vậy từ \((i + 1, k)\) ta có nhiều lựa chọn hơn (và có tất cả lựa chọn của) \((i + 1, nx[i + 1][j])\), nên ta sẽ chọn \((i + 1, k)\).
Khi đã có mảng \(nx[i][j]\), việc truy vết trở thành đơn giản.
desert
Cây khung Manhattan
Bản chất của việc dựng đường đi sao cho cạnh \(\max\) là \(\min\) chính là dựng cây khung nhỏ nhất của đồ thị.
Từ việc chăm chỉ đọc wiki, ta cũng biết có thể dựng lên cây khung giữa các đỉnh theo khoảng cách Manhattan với độ phức tạp \(O(N \log N)\). Thực chất đây chỉ là bài yêu cầu implement thuật toán đó.
Dựng cây khung như nào?
Ta có thể chứng minh rằng, để dựng cây khung Manhattan, với mỗi điểm ta chỉ cần nối cạnh đến đỉnh gần nó nhất trong mỗi góc phần tám. Vậy tìm chúng như thế nào?
Tìm điểm gần nhất trong góc phần tám
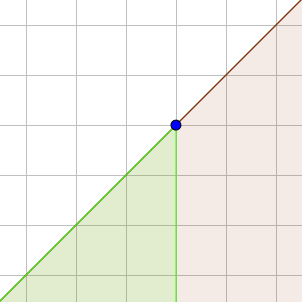
Giả sử ta sẽ giải bài toán cho góc phần tám có \(X \le X_0\), \(Y \le Y_0\) và \(X - Y \le X_0 - Y_0\).
Ta sắp xếp các điểm theo thứ tự \(X_i - Y_i\) giảm dần, và thêm vào một IT có tọa độ được xếp theo \(X_i\) giá trị \(X_i + Y_i\) lấy \(\max\).
Với mỗi điểm, ta get trong IT giá trị
\(X_j + Y_j\) lớn nhất với \(X_j \le X_i\), rồi
cập nhật điểm đó vào IT. Điểm get ra
sẽ là điểm gần nhất theo góc phần tám này.
Để hiểu tại sao sắp xếp như vậy lại đúng, xem hình dưới.
Dễ dàng làm với góc phần tám đối diện, chỉ cần for tập điểm ngược lại.
Giải nhanh tất cả các phần
Thay vì cài tất cả các trường hợp góc phần tám, ta có thể chỉ cần giải 2 góc đối diện như trên, rồi thực hiện phép quay 90 độ cho tất cả các điểm theo gốc, và tiếp tục giải.
Hiển nhiên sau khi xoay 3 lần ta sẽ giải đủ 8 góc phần tám.
Trốn việc
Liên tưởng
Trong một hệ thống \(N\) máy song song, ta phải đảm bảo trong khoảng thời gian \(M\) bất kì không có quá \(N\) thao tác được thực hiện trên bất cứ máy nào. Ta sẽ làm như nào?
Một cách đơn giản là ra lệnh cho một máy, sau khi thực hiện một thao tác, sẽ ngủ trong \(M\) giây. Như vậy, không có khoảng thời gian \(M\) nào có một máy chạy 2 lần, vì thế không có chuyện có nhiều hơn \(N\) thao tác được chạy.
Ta sẽ sử dụng ý tưởng này cho bài toán.
Biến đổi bài toán
Đề bài yêu cầu ta chọn một tập lớn nhất sao cho cứ \(N\) phần tử liên tiếp bất kì có không quá \(K\) phần tử được chọn. Ta sẽ biến bài toán thành: Cho phép chạy \(K\) máy lựa chọn song song, mỗi phần tử chỉ được cho một máy lựa chọn, trong khoảng \(N\) bất kì không có máy nào chọn liên tiếp 2 phần tử.
Nếu \(K = 1\), ta có thể sử dụng quy hoạch động \(f[i] = \max(f[i - 1], f[i - N] + A[i])\). Với \(K\) lớn hơn, ta sẽ phải tìm cách khác để đảm bảo mỗi phần tử chỉ được tối đa một máy lựa chọn.
Hãy tưởng tượng một đường ống \(3N + 1\) đoạn liên tiếp nối thành một đường thẳng. Ngoài ra đường ống thứ \(i\) còn được nối với \(\min( i + N, 3N + 1)\). Từ đỉnh 1 ta cho \(K\) robot chạy về hướng \(3N + 1\). Các robot có thể đi đường \(i\) - \(i + 1\) thoải mái, nhưng mỗi đường đi \(i\) - \(i + N\) chỉ có thể cho 1 robot đi qua, đồng thời sẽ thu về \(A[i]\) đồng tiền. Ta cần thu về nhiều tiền nhất có thể.
Nghe rất giống một bài luồng max cost.
Dựng luồng
Ta áp dụng toàn bộ ý tưởng của đường ống vào luồng.
- \(3N + 2\) đỉnh, \(0\) là nguồn \(3N + 1\) là đích.
- \(0\) => \(1\): cap = \(K\), cost = \(0\)
- Với \(i > 0\), \(i\) => \(i + 1\): cap = \(inf\), cost = \(0\)
- Với \(i > 0\), \(i\) => \(\min(i + N, 3N + 1)\): cap = \(1\), cost = \(A[i]\)
Trên mạng, ta tìm luồng max cost. Hiển nhiên luồng cực đại là \(K\), nhưng ta chỉ cần quan tâm đến cost tối đa. Cost chính là đáp số.
Độ phức tạp là O(luồng 600 đỉnh 1000 cạnh).
Party1
Thay đổi mục tiêu
Thay vì đi tìm những đỉnh mà xuất hiện trong mọi cặp ghép cực đại, ta sẽ tìm những đỉnh không có tính chất đó. Thật vậy, ta sẽ cần tìm những đỉnh mà khi bỏ nó đi, kích cỡ cặp ghép cực đại vẫn không thay đổi.
Tính chất của cặp ghép
Đầu tiên, ta dựng cặp ghép cực đại trên đồ thị đã cho. Hiển nhiên các đỉnh không thuộc cặp ghép là các đỉnh cần tìm. Ta sẽ chỉ xét đến các đỉnh thuộc cặp ghép.
Giả sử \(v_0\) là một đỉnh không được ghép. Xét đường tăng \(v_0, v_1,…, v_{2k}\). Hiển nhiên độ dài đường tăng phải chẵn, nếu không ta có thể tăng số cặp ghép, không thỏa mãn tính chất cặp ghép cực đại.
Ta nhận thấy, nếu xóa đi 1 trong các đỉnh \(v_2, v_4, …,v_{2k}\), ta sẽ tách đường tăng hiện tại ra thành 1 đường tăng lẻ, đồng thời số cặp ghép giảm đi 1. Tuy nhiến, do tồn tại đường tăng lẻ nên ta có thể đảo lại, làm tăng số cặp ghép về như cũ. Vì vậy \(v_2, v_4, …, v_{2k}\) đều là các đỉnh cần tìm.
Nếu một đỉnh \(x\) khi xóa đi không tạo ra đường tăng lẻ nào (nhưng làm giảm số cặp ghép), chắc chắn nó không phải đỉnh cần tìm.
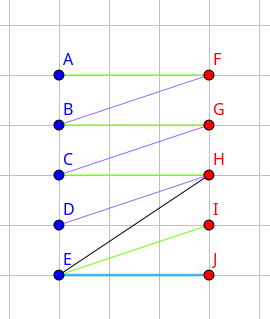
Thuật toán
Trước tiên, tìm cặp ghép. Sau đó, ta BFS từ các đỉnh không được cặp ghép, đi theo các đường tăng, đánh dấu các đỉnh cùng phía được thăm.
Do tính chất của đồ thị 2 phía nên ta chỉ cần 2 lần BFS, mỗi lần xuất phát từ tất cả các đính không được thăm trên cùng 1 phía.
Độ phức tạp sẽ là \(O(K \sqrt{N + M})\) do cặp ghép.
Party2
Nén đồ thị
Với tập đỉnh đỏ, ta sẽ gộp tất cả các đỉnh liên thông lại thành một, cộng tất cả các trọng số lại. Bài toán trở thành tìm tập độc lập cực đại trên đồ thị cạnh xanh.
Đây là một bài NP-Hard, chưa thể giải với giới hạn \(N \le 250\).
Số lượng đỉnh
Một chi tiết quan trọng là số lượng cạnh đỏ rất lớn. Với \(N = 250\) và \(K = \frac{N(N-1)}{3}\), chỉ có tối đa \(46\) đỉnh đã gộp (bao gồm 205 đỉnh có clique và 45 đỉnh bậc 0).
Từ đây, ta có chút hi vọng với thuật backtrack.
Đặt cận!
Đây là danh sách cận cần thiết để hi vọng qua được đống test(?):
- Sort các đỉnh theo bậc rồi backtrack dần
- Xử lí nhanh các đỉnh bị cấm
- Loại bỏ các trường hợp khi tổng các đỉnh còn lại không lớn hơn max hiện tại
- Tính riêng các tplt rồi nhân với nhau